Explained: k-Nearest Neighbours
Netflix, Amazon, Uber and Facebook have used KNN for personalised marketing, clustering, segmentation, and predicting customer behaviour. Measuring distances between data points, the algorithm helps recommend items to customers based on their purchase history An eCommerce store worth it’s salt is always good at one thing – recommendations. A crucial psychological strategy to hold your […]
Topics
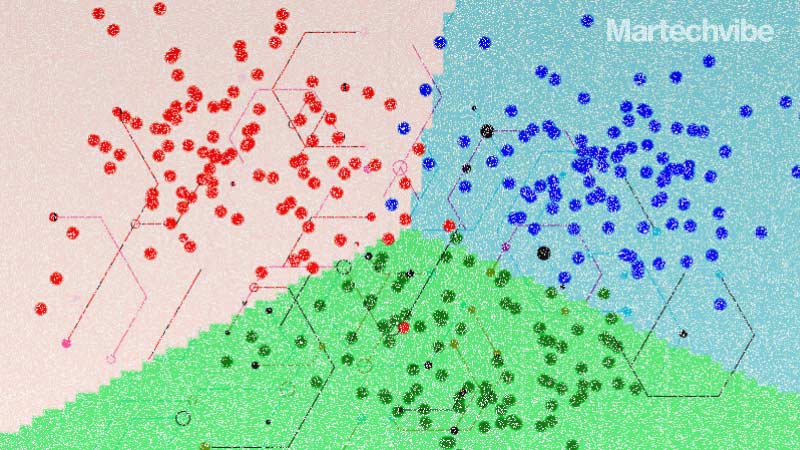
Netflix, Amazon, Uber and Facebook have used KNN for personalised marketing, clustering, segmentation, and predicting customer behaviour. Measuring distances between data points, the algorithm helps recommend items to customers based on their purchase history
An eCommerce store worth it’s salt is always good at one thing – recommendations. A crucial psychological strategy to hold your customers longer in the marketplace or bring them back is to offer them personalised and relevant recommendations based on their purchase history.
As a brand, what’s the best choice to enable the perfect recommendation system for your online store?
The k-nearest neighbours algorithm (KNN or k-NN) is a winning solution. The algorithm uses the distances between data points in a dataset to make predictions or classify new data points.
Evelyn Fix and Joseph Hodges developed the original ideas for the KNN model in a research paper in 1951. Thomas Cover further developed their ideas in his research paper titled “Nearest Neighbor Pattern Classification.”
How does KNN work?
For a recommendation system to work efficiently, a preliminary requirement is the creation of a dataset that includes information about each item in the store, such as its category, colour, size, and price. This should include a list of all the customers who have purchased each item. When a customer makes a purchase, the backend will use the k-nearest neighbours algorithm to find other items identical to the one just purchased.
If the customer bought a blue shirt in size medium, the algorithm would look for other items in the store that are also blue, in size medium, and belong to the same or similar category as the shirt. The algorithm would then recommend the top k items most similar to the customer’s purchase.
Take, for instance, Amazon’s recommendation system, which is powered by machine learning algorithms that use various techniques, including collaborative filtering and k-nearest neighbours. When a customer browses a product on Amazon, the system looks at their browsing and purchase history to find similar products in terms of category, price, features, and other such factors.
However, Amazon is not the only player using KNN;
- Netflix uses the k-nearest neighbours algorithm to recommend movies and TV shows to its users based on their viewing history. The algorithm analyses the user’s past search history (collaborative filtering) and the behaviour of other users with similar viewing habits to make personalised recommendations.
- Uber uses the k-nearest neighbours algorithm to match riders with drivers based on their proximity and availability. The algorithm looks at the location of the rider and the drivers in the area and calculates the distance between each driver and the rider. Uber then selects the driver closest to the rider who’s available to pick them up.
- Facebook uses the k-nearest neighbours algorithm to recommend friends to its users based on their social network. The algorithm analyses the user’s connections on the platform and the connections of other users with similar interests and behaviours to make personalised recommendations.
Applications
One of the KNN algorithm’s primary applications is personalised marketing, where marketers can use the algorithm to provide customised product recommendations to individual customers based on their preferences and past purchases.
Clustering and segmentation are also possible with KNN. Using the algorithm to group customers based on similar characteristics (demographics, behaviour, and interests), brands can better tailor their marketing messages and campaigns to specific groups. This can lead to higher conversion rates.
The KNN algorithm finds another application in predicting customer behaviour and identifying potential sales opportunities. Marketers can predict future actions and adjust their marketing strategies by analysing past customer behaviour and identifying data patterns.
The k-nearest neighbour is a valuable tool for marketers looking to improve their targeting and segmentation, increase customer engagement and retention, and drive sales and revenue.
Limitations
Due to its simplicity and accuracy, the k-nearest neighbours (KNN) algorithm is still among the first algorithms people learn in data science. However, KNN becomes less efficient with an increase in the size of the dataset, affecting the overall model performance.
It can be computationally expensive when dealing with large datasets—the algorithm has to calculate the distance between each data point and all other data points in the dataset, which can be time-consuming and memory-intensive. In addition, KNN can be sensitive to outliers or noisy data points, which can affect the accuracy of the predictions.
The algorithm struggles to make accurate predictions on imbalanced data, where one class of data points is much more prevalent. This can lead to biased predictions and inaccurate model performance.
Despite several limitations, the algorithm is frequently used for simple recommendation systems, pattern recognition, data mining, financial market predictions, and intrusion detection.



